Learn the essential database concepts every developer must know, including data storage, management, and real-world application use cases.

Data is at the core of almost every modern application. Whether it is a web platform handling user accounts, a financial system processing transactions, or an analytics pipeline generating business insights, the ability to store, retrieve, and manage data reliably is critical.
Databases provide the foundation for this data management. They enable applications to handle large volumes of information while maintaining consistency, performance, and availability. As systems grow in scale and complexity, the role of databases becomes even more important, not only from a development perspective but also from an operational and reliability standpoint.
This blog series is designed to build a clear understanding of database fundamentals and then transition into practical implementation and operational aspects. It focuses on how databases are installed, configured, replicated, and troubleshot in real production environments. The goal is to provide a structured path from core concepts to hands-on practices commonly used by engineers and DevOps teams.
What is a Database?
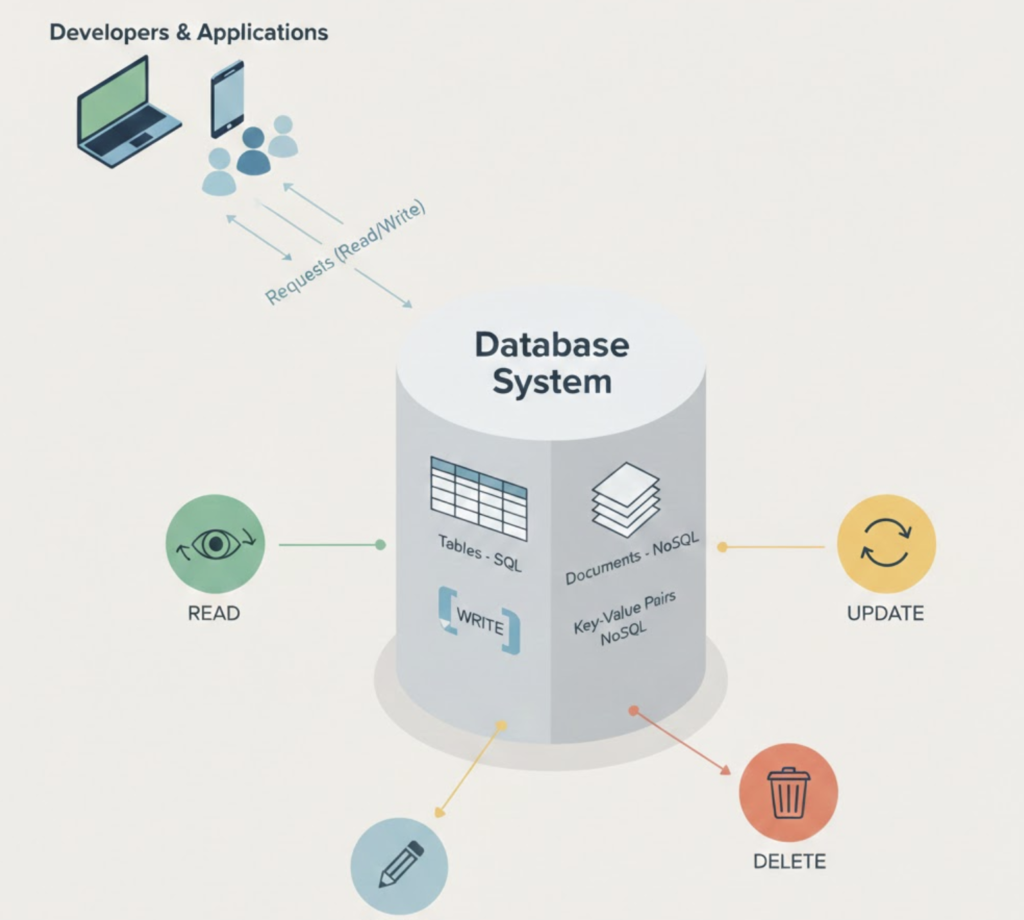
A database is a structured system used to store, manage, and retrieve data efficiently. It is designed to handle large volumes of information while ensuring that data remains accurate, consistent, and accessible to applications and users.
Unlike simple file-based storage, a database provides mechanisms to organize data logically, enforce rules on how data is stored, and allow multiple users or applications to access the data at the same time without conflicts. Databases also support indexing, which enables fast searches, and transaction management, which ensures that operations either complete fully or do not affect the data at all.
In practical terms, a database acts as a centralised and reliable source of truth for an application. User details, transaction records, logs, configuration data, and analytical information are all commonly stored in databases. As applications scale, databases play a critical role in maintaining performance, reliability, and data integrity across distributed systems.
Why Do We Need a Database?
As applications scale, managing data using flat files or basic storage methods becomes inefficient and error-prone. Databases are built to handle these challenges by providing a reliable and structured way to store and manage data.
Databases enable fast and efficient data access through indexing and optimized query execution. They maintain data consistency and integrity by enforcing constraints and supporting transactions, ensuring that data remains accurate even during failures.
They also support concurrent access, allowing multiple users and services to read and write data safely at the same time. In addition, databases provide security and access control, making it possible to protect sensitive information through authentication and permissions.
Finally, databases offer operational reliability with features such as backups, replication, and recovery, which are essential for maintaining availability in production systems.
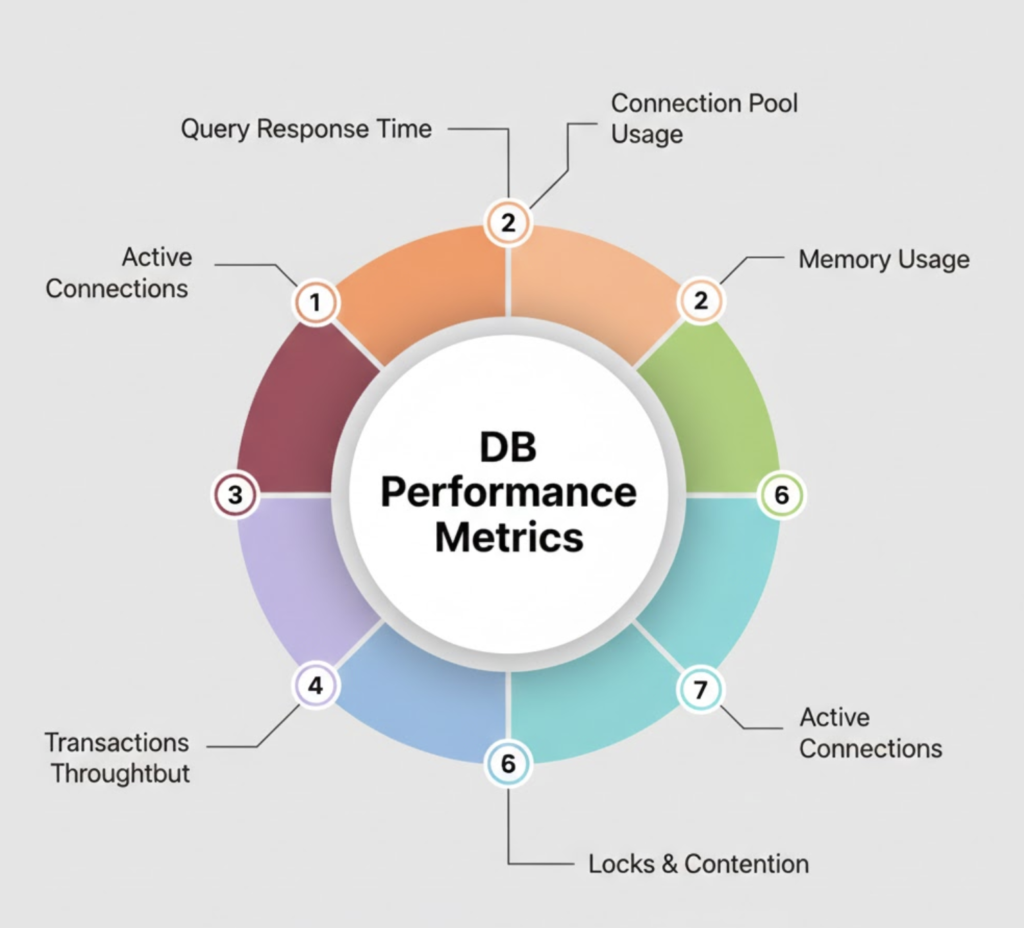
Types of Databases
Databases are classified based on how they store data, enforce structure, and scale to meet application requirements. Understanding these categories helps in selecting the right database for a specific workload.
Relational Databases (RDBMS)
Relational databases store data in structured tables made up of rows and columns. They enforce a fixed schema and define relationships between tables using keys. Data is queried using Structured Query Language (SQL), which provides strong consistency and reliability.
Common use cases include transactional systems, financial applications, and systems where data integrity is critical.
Examples include MySQL and PostgreSQL.
NoSQL Databases
NoSQL databases are designed to handle large volumes of data with flexible or evolving schemas. They are commonly used in distributed systems where scalability and performance are primary concerns.
NoSQL databases can be further categorized into:
- Document databases, which store data as JSON-like documents
- Key-value stores, which store data as simple key-value pairs
- Wide-column stores, which organize data into column families
These databases are well suited for high-throughput workloads, real-time applications, and systems with rapidly changing data models.
In-Memory Databases
In-memory databases store data primarily in system memory rather than on disk. This allows extremely fast read and write operations. They are commonly used for caching, session management, and real-time analytics.
While they offer high performance, in-memory databases often trade off persistence or require additional configuration to ensure durability.
Redis is a commonly used example.
Database Query Languages and Systems
Once the fundamental concepts of databases are clear, the next step is understanding how applications interact with them. This interaction is done through query languages, which provide a structured way to read, write, and manage data within a database system.
It is important to distinguish between a query language and a database system. A query language defines how instructions are written, while a database system is the engine that stores data and executes those instructions.
SQL-Based Systems
Structured Query Language (SQL) is the standard language used by relational databases. It provides a consistent and declarative way to perform operations such as data retrieval, insertion, updates, and schema management.
Popular relational database systems that use SQL include MySQL and PostgreSQL. While both use SQL, their internal architectures, features, and performance characteristics differ.
NoSQL Query Models
NoSQL databases do not rely on traditional SQL and instead use query models tailored to their data structures.
- MongoDB uses document-based queries to work with JSON-like data.
- Cassandra uses CQL (Cassandra Query Language), which resembles SQL but is optimized for distributed, write-heavy workloads.
- Redis uses command-based operations designed for extremely fast access to in-memory data.
Each of these systems is built to solve different problems, and their query mechanisms reflect those design choices.